
ProScanner - Handwritten Text Recognition using Neural Networks
This blog documents my first deep learning project in which we developed a neural network model using Convolutional Neural Networks (CNNs) and Recurrent Neural Networks (RNNs) for Optical Character Recognition to convert handwritten text images into digital text.
INTRODUCTION
The goal of this project is to build a Handwritten Text Recognition (HTR) model to recognize the text in handwritten text-line images and transate them into the corresponding digital format. This problem is relevant as it finds potential applications in several industries like Legal (digitation of case documents), Banking (Automatic reading of cheques, deposit slips etc.), HealthCare (reading prescriptions, handwritten medical records, insurance forms, general health forms etc.), education, government agencies etc. [1] Digitation of paper documents make them easily searchable, editable, accessible and efficient to store.
The dataset that was used for building the model was the IAM Handwriting database. The dataset is described in more detail in the Dataset section. An existing implementation of the HTR model [4] used to recognize individual words from this dataset was taken as a starting point. We took this architecture as a baseline and increased this threshold to 200 characters, therefore greatly increase utility in recognizing full sentences.
A google survey was administered to calculate the human correct recognition accuracy rate. A total of 10 random words and 10 lines were used from the model training data to gauge this. For a total of 42 responses, the overall character error rate was 11.7% (i.e. taking into account all the characters in the 10 words and 10 lines correctly recognized by the 42 responders). For our final model, we got a character error rate of 10.5% for the validation set which is similar to the human character error rate determined.
Although our model was performing satisfactorily, there still are several potential improvements that can be experimented with in order to make the model more accurate and robust. These potential improvements are discussed in the Conclusion Section.
DATASET
The IAM Handwriting Database [2] [3] was used for training the model. This dataset was first published at the ICDAR in 1999. The database contains forms of unconstrained handwritten text, which were scanned at a resolution of 300dpi and saved as PNG images with 256 gray levels. 657 writers contributed handwriting samples to this database. The dataset contains 1,539 pages of scanned text, 5,685 isolated and labeled sentences, 13,353 isolated and labeled text lines and 115,320 isolated and labeled word. Our primary analysis. Our primary focus of interest was the ~13k labeled text lines which were used for training the model. The dataset contained around 80 distinct characters (lowercase, uppercase, digits, symbols).
The following figure depicts examples of images present in the training data:

MODEL TRAINING AND VALIDATION
MODEL TRAINING CONSTRUCT
The dataset of ~13k observations was divided into 95% training Set (~12.4 observations) and 5% validation set (~600 observations). All 12.4k observations were trained in all epochs and each epoch was divided into 50 batches per epoch. The loss function which was minimized was the tensoflow ctc loss tf.nn.ctc_loss. This loss function was used to update the parameters, however we wanted to have a more consumable and intuitive loss function to understand the model performance. In order to do so, we used the character error rate (Avg. % of characters wrongly predicted) and the word error rate Avg. % of words wrongly predicted) to measure model performance. Early stopping was used to prevent overfitting the model. If the model character error rate did not improve for five consecutive epochs, the model training was stopped and the latest model snapshot was taken as the final model object for that iteration.
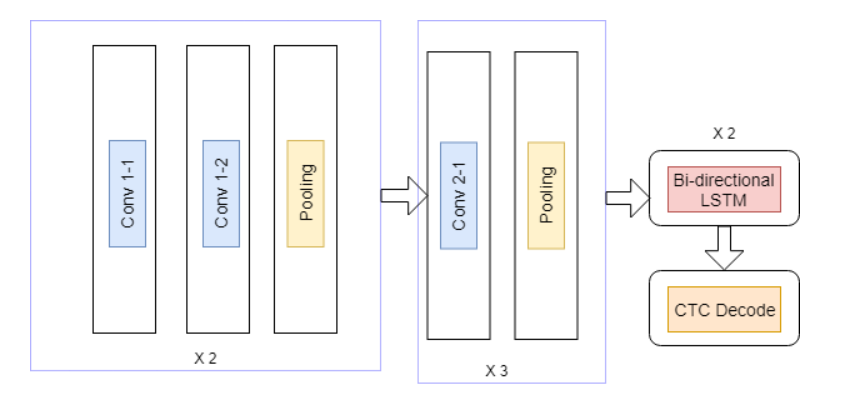
MODEL ARCHITECTURE
Each input training example that is fed into the CNN has a dimension of 800 X 32. Several different hyperparameter combinations (number of CNN layers, number of CNN layer features, dropout, optimization algorithm etc) were modeled to identify the best performing model. The final model architecture involves 7 CNN layers, 2 RNN (LSTM) layers and the CTC loss and a decoding layer and utilized the RMSProp optimizer.
CONVOLUTIONAL NEURAL NETWORK (CNN)
CNN layers extract relevant features from the input image fed during training. The model architecture contains five convolution blocks. The first two blocks consist of two convolution layers with a filter kernel of size 5X5 and RELU activation followed by a pooling layer. The next three blocks consist of one convolution layer each with a filter kernel of size 3X3 and RELU activation followed by a pooling layer. While the image height is downsized by 2 in each block, feature maps (channels) are added, so that the output feature map (or sequence) has a size of 200×256.
RECURRENT NEURAL NETORK (RNN)
Bi-directional Long Short-Term Memory (LSTM) implementation of RNNs is used, as it is able to propagate information through longer distances and provides more robust training characteristics than vanilla RNN. The feature sequence contains 256 features per time-step, the LSTM propagates relevant information through this sequence. The RNN output sequence is mapped to a matrix of size 200×81. The IAM dataset consists of 80 different characters, further one additional character is needed for the CTC operation (CTC blank label), therefore there are 81 entries for each of the 200 time-steps.
CONNECTIONIST TEMPORAL CLASSIFICATION (CTC)
While training the Neural Network, the CTC is given the RNN layer output matrix and the ground truth text and it computes the loss value. While inferring, the CTC is only given the matrix and it decodes it into the final text employing Word Beam Search. Both the ground truth text and the recognized text can be at most 200 characters long.
The following figure depicts the final model architecture:
MODELING RESULTS
The model was trained for 6 hours for 35 epochs on a GTX 960M GPU.
PERFORMANCE METRICS
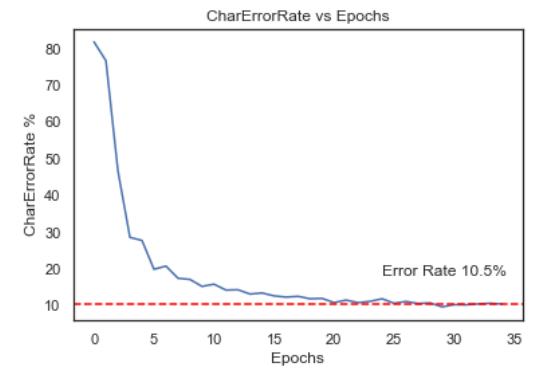
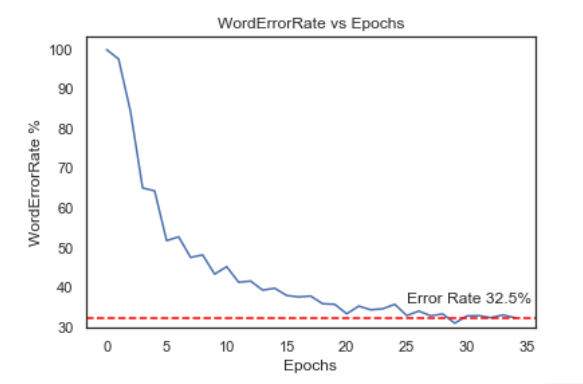
We were able to achieve a character error rate of 10.5% which is similar to a human character rate of 11.7% (determined via a survey). The word error rate was 32.5% indicating that although the model was able to identify most of the characters in the image, it was not very capable of correctly identifying and spelling out full words. The following charts show the model performance characteristics:
SAMPLE OUTPUTS
EXAMPLE 1

Predicted as “by her sufferingar , he said bitterty ;”
EXAMPLE 2
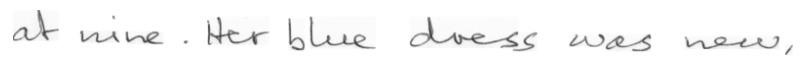
Predicted as “at nine. Her blue drecc was new;”
EXAMPLE 3
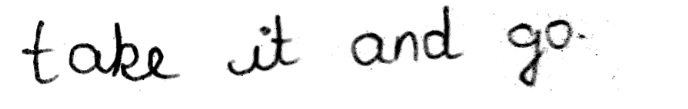
Predicted as “take it and go..”
EXAMPLE 4

Predicted as “Need to get AVC horewark done”
PIXEL RELEVANCE ANALYSIS
Pixel relevance analysis helps us understand what pixels within the original input image were more impactful than others in determining the final output. Below is a pixel relevance chart for the word dress from example 2 above. Red represents that the pixel was more impactful in determining the output, and blue represents that the pixel was not very relevant in determining the output.

Here we see that the writer chose to write the ‘s’ in dress as to small upper case ‘s’s as opposed to the lower case ‘s’ as we see in the next word, ‘was’. Also we observe that the upper arcs of the ‘s’ in the word dress are accentuated. We can see that the upper arc of the first ‘s’ in dress is marked red, while the lower arc is marked blue, this means that the pixels in the upper arc contribute positively to the prediction while the ones in the lower arc contribute negatively. Given that the prediction is ‘drecc’, this makes intuitive sense.
CONCLUSION
Our model performs well on the validation set as well as custom supplied examples. We are able to achieve a character error rate of 10.5% and a word error rate of 32.5%. While our model performance is satisfactory, there is still scope of improvement in our analysis. Firstly, our survey population of 42 respondents is very low for us to report a statistically significant result for human performance. A more extensive study needs to be conducted to determine this accurately. Secondly, we have used a Vanilla Beam Search as our final layer to determine the identified characters. Commercial OCRs use Word Beam Search to search the predicted words within the language dictionary which helps improve the character error rate. This can be implemented to improve our model performance. Thirdly, although we have handwriting samples from ~650 writers, this still is not very representative of all the handwritings that the model could encounter. Data augmentation could potentially be done to generate synthetic data so train the model on more varied handwriting samples.



Leave a comment